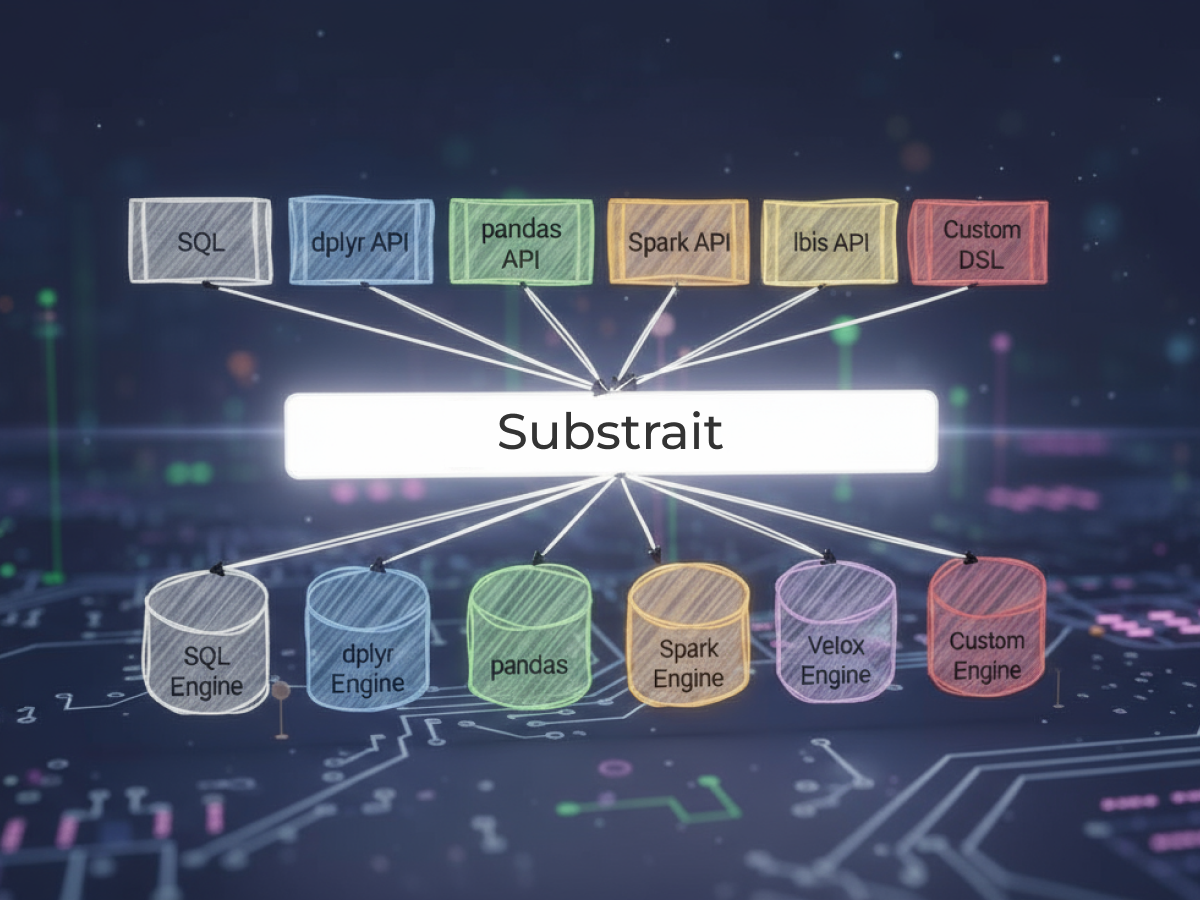
Composable Data Systems: Lessons from Apache Calcite Success
Apache Calcite achieved tremendous success, powering query optimization in many popular systems, such as Apache Hive and Apache Flink. But even though such a great library has existed for more than ten years, query optimization development is still remarkably complicated and hardly "commoditized." Why is it so? We will discuss which exact technical decisions contributed to Apache Calcite's success, what role community plays in such projects, why it is still so difficult to integrate "composable" libraries into real products, and why I personally do not believe that composable data systems trend will fundamentally change the competition dynamics in the market.