
Often, required data resides in different storages: for example, sales data is in Parquet/S3, while catalog data is in Postgres. A business question requires one query across all of it (e.g., joining sales with products).
To achieve this, one can use a federated engine (CedrusData / Trino / Dremio / Presto), which parses SQL written by an analyst, builds a unified execution plan, and pushes down fragments of the plan to data sources: filters and projections to Parquet readers, subqueries to Postgres, etc.
For Postgres, the federated engine uses a JDBC connector. This usually means that after optimization, the federated engine must regenerate SQL in the target database’s dialect, send it there, fetch intermediate results, and compute the rest of the plan (joins across sources, final aggregations) locally.
But this approach has a number of specific problems:
The Idea of Substrait - Instead of sending a SQL string, Substrait proposes to transmit a serialized query plan - an intermediate representation (IR) in protobuf, with well-defined operators, types, and functions.
This enables:
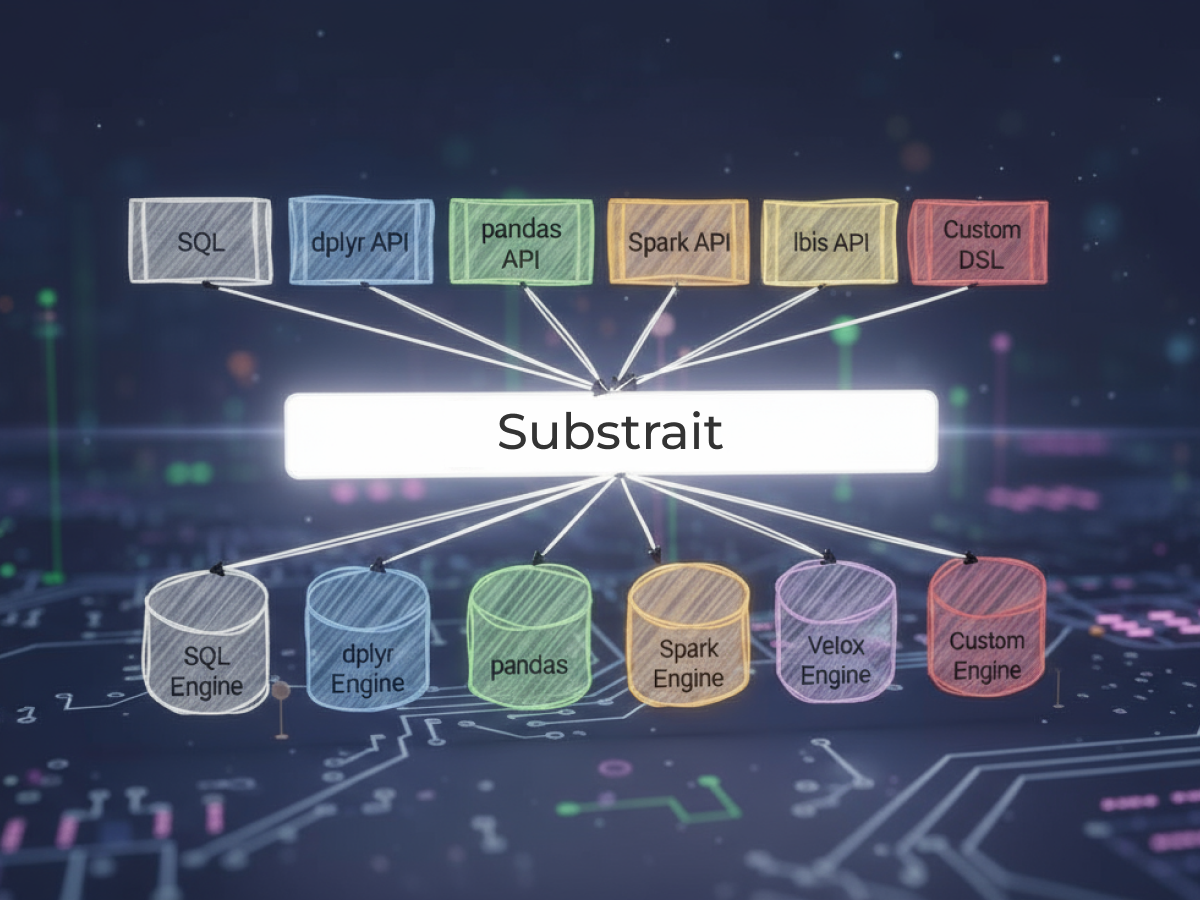
Substrait's place in the world of DBMS is well illustrated by the following illustration:

When Substrait Is Not Needed:
Substrait is an open, language- and engine-agnostic specification of a portable IR for relational computations over structured data.
Plans are defined in Protocol Buffers (with a human-readable text form), and YAML catalogs describe extensions - functions, expressions, relational operators, types, and their variants.
The basic building blocks of Substrait are shown in this figure:

One system that generates plans is called a producer, and the one that consumes and executes them - a consumer.
Before executing anything, systems can exchange their capabilities (capabilities.proto), so both sides understand what the other supports. This includes the Substrait version and lists of supported functions and types - described via SimpleExtensions.
A typical YAML extension (e.g., functions_arithmetic.yaml) looks like this:
urn: extension:io.substrait:extension_types
types:
- name: point
structure:
latitude: i32
longitude: i32
- name: line
structure:
start: point
end: pointThis capabilities exchange step is optional - one can start sending plans right away, assuming both sides understand the same extensions.
When a user requests data in any format (SQL, Python, dplyr, etc.), the producer converts it into a Protobuf message in accordance with the Substrait specification.
To make this clearer, let's look at a typical use case for pushing a subquery to another system. For example, we need to execute this query:
-- Sum of sales where price > 100
SELECT SUM(amount) AS total_amount
FROM sales
WHERE price > 100;The sales table is in Parquet.
Our Parquet reader can perform simple filtering (the WHERE clause), but not aggregation (SUM).
The producer generates a Substrait plan and sends it to the consumer:
{
// List of extensions (functions and types) used
"extensions": [
// The namespase for extensions has anchor=1, this is the link by which the function is bound to the namespace.
{ "extensionUri": { "uriAnchor": 1, "uri": "urn:substrait:functions_comparison" } },
// The definition of the function used is "gt," short for "greater than." It has an anchor that links to it below.
{ "extensionFunction": { "functionAnchor": 1, "name": "gt", "uriReference": 1 } }
],
"relations": [
{
// Relational expression tree
"root": {
"input": {
"project": { // The projection operator SELECT(amount) which discards extra columns
"input": {
"filter": { // Filter operator WHERE price > 100
"input": {
"read": { // Table Read Operator and Table Schema
"namedTable": { "names": ["sales"] },
"baseSchema": {
"names": ["id", "price", "amount"],
"struct": {
"types": [
{ "i64": {} },
{ "i32": {} },
{ "i32": {} }
]
}
}
}
},
"condition": { // The argument of the filter operator - predicate price > 100
"scalarFunction": {
"functionReference": 1, // gt(x, y) - the “Greater than” operation with anchor=1 (see the definition of extensionFunction at the beginning)
"arguments": [
{
"value": {
"selection": {
"directReference": { "structField": { "field": 1 }} //price field #1
"rootReference": {}
}
}
},
{ "value": { "literal": { "i32": 100 } } } // Literal “100” of integer 32
]
}
}
}
},
"expressions": [ // The argument of the project operator: select the ‘amount’ column.
{
"selection": {
"directReference": { "structField": { "field": 2 } }, // Amount - field #2
"rootReference": {}
}
}
]
}
},
"names": ["amount"] // The final projection of the “root” node
}
}
]
}
The consumer executes the plan and returns the filtered amount column (price > 100).
The producer aggregates it locally (SUM(amount)) and returns the final result.
Thus, we executed a federated query without parsing SQL, without dialect headaches, and without regenerating SQL for subqueries.
The example above shows just one scenario where Substrait would be useful: pushing a subquery to another system. But there are other use cases for Substrait.
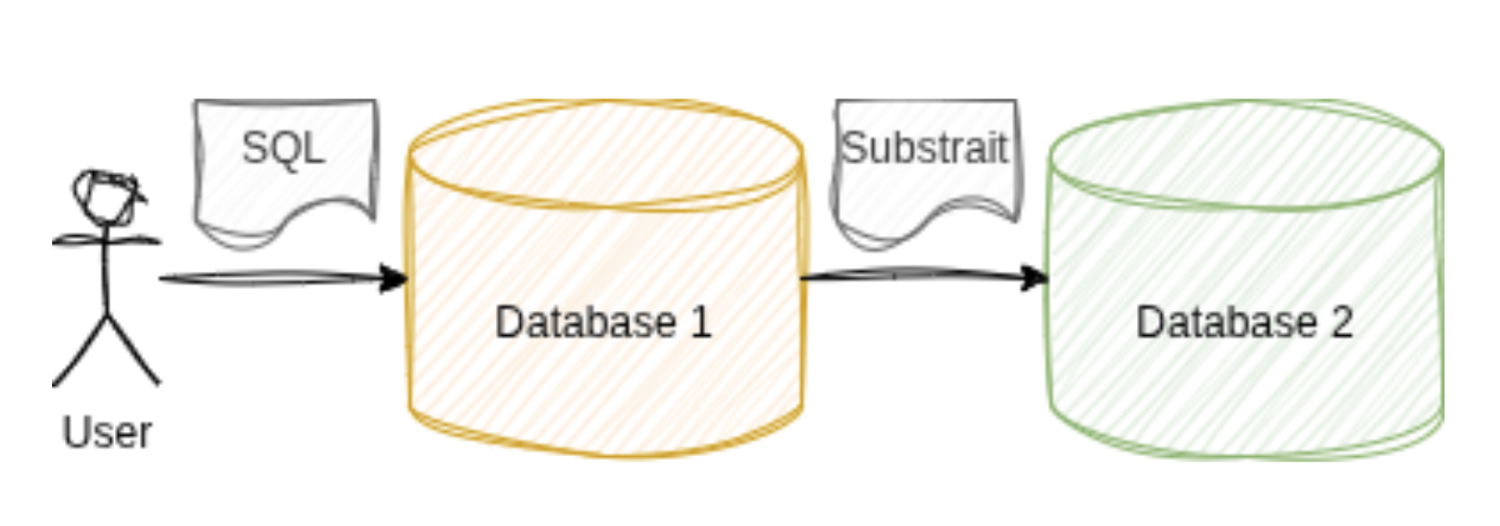
As shown above - one system sends a subquery plan to another (or several).
Database 1 must know the others’ capabilities (e.g., don’t send joins to a Parquet reader).

Here, Database 1 need not know the capabilities of Database 2.
It can send the entire plan, and Database 2 executes what it can, returning the residual part (still in Substrait) to be executed by Database 1.
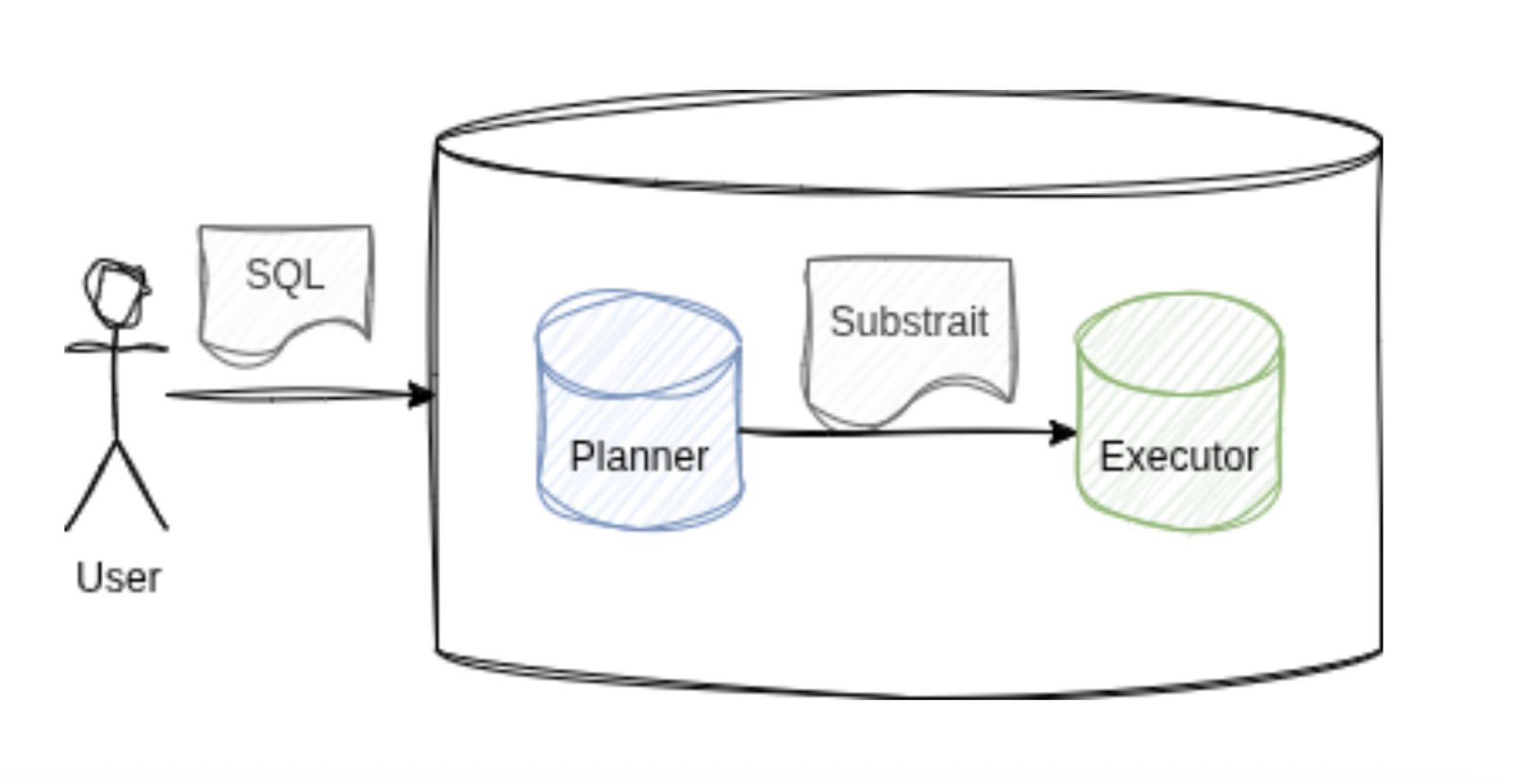
Substrait can also replace an internal IR for communication between the query planner and execution engine. This makes swapping engines easier.
For example, Spark + Gluten uses Substrait for physical-plan translation into native execution (Velox and others).
Substrait brings us closer to a world where frontends (SQL / Ibis / dplyr / …) and backends (Velox / DuckDB / DataFusion / …) can be freely combined.
It’s not a silver bullet — semantics alignment, validation, and observability are still required — but the gains in integration speed and logic portability are well worth it.
We help technology companies build innovative data management products.
QUERIFY LABS SOFTWARE DEVELOPMENT - FZCO
License Number: 55968
Address: Building A1, Dubai Digital Park, Dubai Silicon Oasis, Dubai, United Arab Emirates